NTP服务端:linl_S IP:10.0.0.15
NTP客户端:lin_C IP:10.0.0.16
NTP服务概述
1、原理
NTP(Network TimeProtocol,网络时间协议)是用来使计算机时间同步的一种协议。它可以使计算机对其服务器或时钟源做同步化,它可以提供高精准度的时间校正(LAN上与标准间差小于1毫秒,WAN上几十毫秒),切可介由加密确认的方式来防止恶意的协议攻击。
模式:C/S模式
运行模式:
2、端口(123)
1 [root@linl_S ~]# vim /etc/services 2 nntp 119/tcp readnews untp # USENET News Transfer Protocol 3 nntp 119/udp readnews untp # USENET News Transfer Protocol 4 ntp 123/tcp 5 ntp 123/udp # Network Time Protocol
拓展:
NNTP(Network News Transport Protocol),中文释义:(RFC-977)网络新闻传输协议。这是一个主要用于阅读和发布新闻文章(俗称为“帖子”,比较正式的名字是“新闻组邮件”)到Usenet 上的Internet应用协议,也负责新闻在服务器间的传送。
安装NTP
默认是已安装,如果是最小化安装系统,则需要手动安装。
1)NTP相关软件包
1 [root@linl_S ~]# ls /mnt/Packages/ntp* 2 /mnt/Packages/ntp-4.2.6p5-1.el6.x86_64.rpm #NTP服务端软件包 3 /mnt/Packages/ntpdate-4.2.6p5-1.el6.x86_64.rpm #NTP客户端软件包
2)安装NTP服务端软件包:
1 [root@linl_S ~]# yum -y install ntp #NTP两个软件包都会安装上 2 ... 3 Installed: 4 ntp.x86_64 0:4.2.6p5-1.el6 5 Dependency Installed: 6 ntpdate.x86_64 0:4.2.6p5-1.el6 7 Complete!
安装客户端:
1 [root@linl_C ~]# rpm -ivh /mnt/Packages/ntpdate-4.2.6p5-1.el6.x86_64.rpm #只安装ntpdate安装包 2 warning: /mnt/Packages/ntpdate-4.2.6p5-1.el6.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID fd431d51: NOKEY 3 Preparing... ########################################### [100%] 4 package ntpdate-4.2.6p5-1.el6.x86_64 is already installed
NTP配置文件所在位置
1 [root@linl_S ~]# ls /etc/ntp.conf 2 /etc/ntp.conf
3)启动NTP服务
1 [root@linl_S ~]# service ntpd start #启动ntp服务 2 Starting ntpd: [ OK ] 3 [root@linl_S ~]# netstat -anptu |grep 123 #查看端口123是否开放 4 udp 0 0 10.0.0.15:123 0.0.0.0:* 5846/ntpd 5 udp 0 0 127.0.0.1:123 0.0.0.0:* 5846/ntpd 6 udp 0 0 0.0.0.0:123 0.0.0.0:* 5846/ntpd 7 udp 0 0 fe80::20c:29ff:fea9:c1ae:123 :::* 5846/ntpd 8 udp 0 0 ::1:123 :::* 5846/ntpd 9 udp 0 0 :::123 :::* 5846/ntpd 10 [root@linl_S ~]# chkconfig ntpd on #开机自启动
实战1:手动同步NTP时间服务器
1)在lin_S服务器上查看可用的NTP时间服务器
1 [root@linl_S ~]# vi /etc/ntp.conf 2 # Use public servers from the pool.ntp.org project. 3 # Please consider joining the pool (http://www.pool.ntp.org/join.html). 4 server 0.rhel.pool.ntp.org iburst #找一个可以使用的NTP时间服务器 5 server 1.rhel.pool.ntp.org iburst 6 server 2.rhel.pool.ntp.org iburst 7 server 3.rhel.pool.ntp.org iburst
2)在lin_C客户端上与NTP时间服务器进行同步
1 [root@linl_C ~]# ntpdate 0.rhel.pool.ntp.org 2 22 May 22:04:41 ntpdate[5733]: adjust time server 202.118.1.130 offset 0.027428 sec
拓展:
在lin_S服务端(已启动NTP服务)与NTP时间服务器进行同步会报错。
1 [root@linl_S ~]# ntpdate 0.rhel.pool.ntp.org 2 22 May 22:06:17 ntpdate[2464]: the NTP socket is in use, exiting
问题分析:
出现该错误的原因是lin_S服务器正在运行ntpd服务,就不能用ntpdate来手动更新时间了。
解决方法:
关闭ntpd服务
1 [root@linl_S ~]# service ntpd stop 2 Shutting down ntpd: [ OK ] 3 [root@linl_S ~]# ntpdate 0.rhel.pool.ntp.org 4 22 May 22:13:27 ntpdate[2495]: adjust time server 202.118.1.130 offset -0.068183 sec
实战2:搭建内网NTP服务器,内网服务器通过此NTP服务器进行时间同步
1)修改NTP配置文件
蓝色底纹部分为增加项
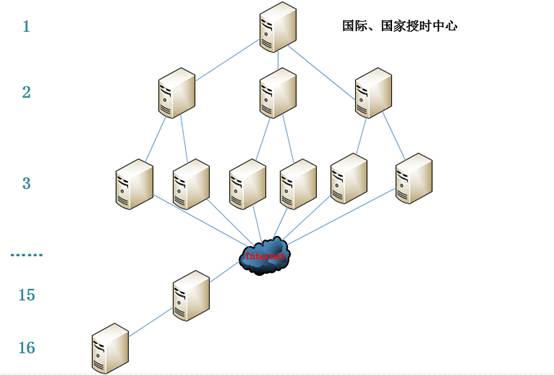
1 [root@linl_S ~]# vi /etc/ntp.conf 2 # Permit all access over the loopback interface. This could 3 # be tightened as well, but to do so would effect some of 4 # the administrative functions. 5 restrict 127.0.0.1 6 restrict -6 ::1 7 restrict 10.0.0.0 mask 255.255.255.0 #允许10.0.0.0 网段中的服务器访问本ntp服务器进行时间同步 8 restrict 10.0.0.16 #允许单个IP地址访问本ntp服务器 9 # Use public servers from the pool.ntp.org project. 10 # Please consider joining the pool (http://www.pool.ntp.org/join.html). 11 server 210.72.145.44 #指定本ntp服务器的上游ntp服务器为210.72.145.44,并且设置为首先服务器。同步时间为:从上到下,写的越靠上,优先级越高。(此服务器同步不了时间,寻找下一个ntp服务器)。此IP地址是中国国家授时中心ntp服务器。 12 server 133.100.11.8 #当上面服务器同步不了,则寻找第二个。此IP地址是日本福冈大学ntp服务器。 13 server 0.rhel.pool.ntp.org iburst 14 server 1.rhel.pool.ntp.org iburst 15 server 2.rhel.pool.ntp.org iburst 16 server 3.rhel.pool.ntp.org iburst 17 server 127.127.1.0 #local clock 如果上面的服务器都无法同步时间,就和本地系统时间同步。127.127.1.0在这里是一个IP地址,不是网段。 18 fudge 127.127.1.0 stratum 10 #127.127.1.0 为第10层。ntp 和127.127.1.0同步完后,就变成了11层。 ntp是层次阶级的。同步上层服务器的stratum 大小不能超过或等于16。
2)启动ntpd服务
1 [root@linl_S ~]# /etc/init.d/ntpd start 2 Starting ntpd: [ OK ] 3 [root@linl_S ~]# netstat -ln |grep 123 4 udp 0 0 10.0.0.15:123 0.0.0.0:* 5 udp 0 0 127.0.0.1:123 0.0.0.0:* 6 udp 0 0 0.0.0.0:123 0.0.0.0:* 7 udp 0 0 fe80::20c:29ff:fea9:c1ae:123 :::* 8 udp 0 0 ::1:123 :::* 9 udp 0 0 :::123 :::*
指令“ntpq -p”可以列出目前我们的NTP与相关的上层NTP的状态,以上的几个字段的意义如下:
remote:即remote – 本机和上层ntp的ip或主机名,“+”表示优先,“*”表示次优先。
refid:参考的上一层NTP主机的地址
st:即stratum阶层
poll:下次更新在几秒之后
offset:时间补偿的结果
1 [root@linl_S ~]# ntpq -p #列出本NTP服务器与上游服务器的连接状态 2 remote refid st t when poll reach delay offset jitter 3 ============================================================================== 4 210.72.145.44 .INIT. 16 u - 64 0 0.000 0.000 0.000 5 133.100.11.8 .INIT. 16 u - 64 0 0.000 0.000 0.000 6 *dns1.synet.edu. 202.118.1.47 2 u 32 64 3 60.058 7.261 6.860 7 news.neu.edu.cn .INIT. 16 u - 64 0 0.000 0.000 0.000 8 202.118.1.130 .INIT. 16 u - 64 0 0.000 0.000 0.000 9 42.96.167.209 .INIT. 16 u - 64 0 0.000 0.000 0.000 10 LOCAL(0) .LOCL. 10 l 96 64 2 0.000 0.000 0.000 11 [root@linl_S ~]# ntpstat #列出是否与上游服务器连接。需要过5分钟 12 synchronised to NTP server (202.112.29.82) at stratum 3 #可以看到我们当前在3层 13 time correct to within 257 ms #ms 毫秒是一种较为微小的时间单位,是一秒的千分之一。 14 polling server every 64 s
4)客户端同步时间
1 [root@linl_C ~]# date -s "2015-5-23 11:30" #先设置一个错误的时间点 2 Sat May 23 11:30:00 CST 2015 3 [root@linl_C ~]# ntpdate lin_S #进行ntp时间同步 4 23 May 11:34:10 ntpdate[6686]: step time server 10.0.0.15 offset 31622622.275270 sec 5 [root@linl_C ~]# date 6 Mon May 23 11:34:16 CST 2016 #时间同步成功
常见错误:如下所示。
其实,这不是一个错误。而是由于每次重启NTP服务器之后大约要3-5分钟客户端才能与server建立正常的通讯连接。当此时用客户端连接服务端就会报这样的信息。一般等待几分钟就可以了。
1 [root@linl_C ~]# ntpdate lin_S 2 23 May 11:38:02 ntpdate[6694]: no server suitable for synchronization found
5)和NTP相关的配置文件
/etc/sysconfig/clock #这个是linux 的主要时区设定文件。每次开机后,Linux会自动的读取这个文件来设定自己系统所默认要显示的时间。
1 [root@linl_S ~]# cat /etc/sysconfig/clock 2 # The time zone of the system is defined by the contents of /etc/localtime. 3 # This file is only for evaluation by system-config-date, do not rely on its 4 # contents elsewhere. 5 ZONE="Asia/Shanghai"
拓展1:linux系统时间和BIOS时间是不是一定一样?
查看硬件BIOS时间:
hwclock -r 读出BIOS的时间参数
hwclock -w 将当前系统时间写入BIOS中
1 [root@linl_C ~]# date -s "2016-5-22 13:50" 2 Sun May 22 13:50:00 CST 2016 3 [root@linl_C ~]# hwclock -r 4 Mon 23 May 2016 01:53:50 PM CST -0.110948 seconds 5 [root@linl_C ~]# hwclock -w 6 [root@linl_C ~]# hwclock -r 7 Sun 22 May 2016 01:50:48 PM CST -0.783098 seconds #已将系统date时间写入到BIOS时间
拓展2:不同机器之间的时间同步
为了避免主机时间因为长期运作下所导致的时间偏差,进行时间同步(synchronize)的工作是非常必要的。
同步时间,可以使用ntpdate命令,也可以使用ntp服务。
方法一:使用ntpdate 比较简单。格式如下:
1 [root@linl_C ~]# ntpdate lin_S 2 23 May 19:50:44 ntpdate[7507]: step time server 10.0.0.15 offset 1.239826 sec
但这样的同步,只是强制性的将系统时间设置为ntp 服务器时间。只是治标不治本。所以,一般配合cron命令,来进行定期同步设置。比如,在crontab 中添加:
1 [root@linl_C ~]# crontab -e 2 0 12 * * * /usr/sbin/ntpdate lin_S
方法二:使用ntpd 服务进行同步。
要注意的是,ntpd 有一个自我保护设置:如果本机与上源时间相差太大,ntpd 不运行。所以新设置的时间服务器一定要先ntpdate 从上源取得时间初值。然后启动ntpd 服务。
转载自:https://www.cnblogs.com/shanhua-fu/p/9281040.html